
Legal Innovation & Technology Lab@ Suffolk Law School
Why Data Science? A.K.A. Bureaucrats and Mathemagicians: Data Science and the Public Defenders
Estimated Time (Reading): ~10 min.A version of this essay by David Colarusso originally appeared in the ABA's Law Technology Today. The following has been edited for style and updated to reflect developments in the litigation cited.
When I transitioned from my role as a public defender to that of a data scientist, a fellow attorney quipped, "What does that even mean?" This is unsurprising given that many still debate the definition and utility of "data science as a moniker." The pithy answer? "Data science is storytelling with error bars." For a more robust reply, let me share a story.
In 2012, it was discovered that a chemist working at the Massachusetts state drug lab in Jamaica Plain had been falsifying drug tests (e.g., claiming that samples contained narcotics without testing them and even adding cocaine to samples to get a positive result when prior testing came back negative). She had worked at the lab for nearly a decade, and these revelations called into question the outcomes in tens of thousands of cases. Yet even now, years after a guilty plea from the chemist on charges of evidence tampering and obstruction of justice and the dismissal of tens of thousands of cases, there is no definitive list of affected parties.
Early attempts were made to construct such a list. The most comprehensive of these involved an exhaustive examination of records from the drug lab. This included the contents of the lab's electronic records and physical files. To create a "master list" of affected parties, these were examined, and if our rogue chemist was found to have been the primary or secondary chemist on a test, the names cited as "Defendant(s)" for said test were added to The List. Our story focuses on a single link in the chain of custody: a form called the drug receipt. Provided by the police along with the sample for testing, said receipts included the names of defendants associated with samples. As such, they proved one of the best sources for establishing the names of people affected by the results of a test.
Attorneys working on behalf of those defendants affected by the chemist's actions had some questions, however. For example, "How sure are we that all parties associated with a sample were listed in a file, namely on the sample's receipt?" They knew that different police departments used different formats, and for some, the space for "defendant(s)" was quite limited. What if there were more defendants than could fit in the space provided? These questions would not have lingered if the names had been supplemented with additional information such as that from relevant police reports. This, however, was beyond the scope of The List's compilation. Eventually, the Committee for Public Counsel Services (CPCS), decided to see if data could help clarify what was going on.
In Massachusetts, indigent criminal defense is managed by the Committee for Public Counsel Services and delivered by either government attorneys working for the Committee or private attorneys who contract with the Committee. I was one of those government attorneys but after a few years I began work as their first data scientist, and it was in that capacity that I found myself on a team of people working to help shed light on what we came to call the missing Co-D problem.
If The List were complete, one would expect to find all co-defendants on The List together, assuming they were charged in relation to the same "drug" sample. The problem was how to determine if this was the case given the limited information available to CPCS. Luckily, in addition to The List, CPCS had access to its staff attorneys' case files, including police reports and lists of co-defendants. Staff attorneys take only a small fraction of indigent cases. The majority are handled by private attorneys. So only a subset of defendants on The List would be in the staff attorneys' client files. However, given The List contained nearly 40,000 names, this subset was still rather sizable. So we used some nice open source software (the subject of subsequent lessons) to look for matches between our clients' names and those found on the list (this involved some data wrangling in Python and Pandas along with the creation of a nice IPython/Jupyter Notebook or two). This gave us a rough list of clients on The List, and we used these names to create a list of their co-defendants. We then checked The List for these co-defendant names. Unfortunately, a lot of them were missing. If we assumed the same rate of missing names across all cases, it seemed The List was missing somewhere between 0 and 9,600 names. Wait, what? That's right, thousands of potentially missing names. The uncertainty came from the fact that we had to match names. The List did not come with dates of birth, addresses, or Social Security Numbers—just names. So occasionally, we could not find a name we were looking for because the Commonwealth and CPCS disagreed on the spelling of a name or someone made a transcription error. To get a better feel for what was really going on, we chose a small (statistically insignificant) number of client names and pulled the police reports in their cases. This led us to find a number of cases where co-defendants had in fact been left off The List. Consequently, the missing names were no longer theoretical. In reality, though, there were likely hundreds of missing names, not thousands. Unfortunately, that still translates to hundreds of people who slipped through the cracks; hundreds of people who may be entitled to some type of legal relief.
As part of litigation, the involved DAs were ordered to produce enhanced lists, including additional identifying information for defendants and docket numbers relating to the samples found on The List. After originally producing lists where none of the missing Co-Ds were listed and claiming that their lists were over-inclusive, they were presented with the results of the above analysis, and most of the DAs subsequently produced list containing some number of missing Co-Ds. When the issue was theoretical, it was easy to ignored the problem. To find all of the missing names, someone would likely have had to read through tens of thousands of police reports, and it seems that this probably didn't happen. Those DAs that added Co-Ds to their lists seemed to be those with electronic case management systems that made the search easier. For those who argue that reading through tens of thousands of reports to find a few hundred names is not worth it, I respond with the words of Judge Learned Hand: "If we are to keep our democracy, there must be one commandment: Thou shalt not ration justice." An oversight was made in compiling The List. It should be corrected. That story is clear, and it comes with error bars. In a victory for those affected by the chemist's actions, however, over 20,000 cases were dismissed and a presumption favorable to the defendants was set for those who later discover that their case was affected.
You might be saying, "Wait, this is data science? This sounds like grade school arithmetic and record keeping 101," and your skepticism would be warranted. The real promise is in catching the next scandal early, though the next scandal came quite soon, so maybe the next scandal after that. This means listening to data and looking for patterns. The rogue chemist had a throughput three times that of the next "most productive" chemist. That should have been a red flag. Data science offers the promise of mining data for signals such as these and sounding the alarm. It is a way to make use of what an institution knows in theory, a way to create insight from data, a tool to help identify and connect the dots.
Data science does this by identifying a question and finding a way to answer it with data. Often this means running data through an algorithm to produce some prediction or classification. Framed this way, maybe it really is nothing new. However, I am not ready to abandon the moniker quite yet. Despite its youth, it comes laden with a set of useful cultural norms. These are exemplified in a definition from Drew Conway, a definition that comes in the form of a Venn Diagram.
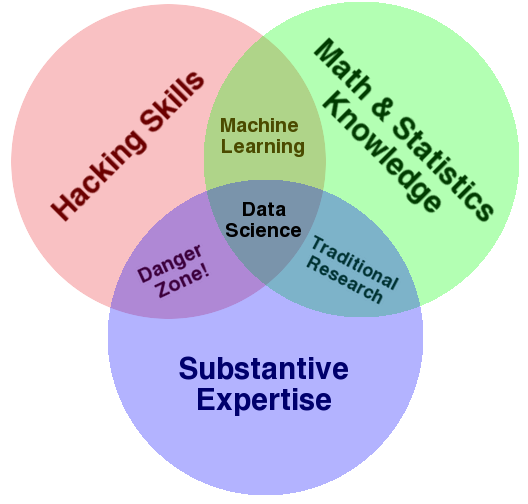
His description of the diagram is worth the read, but mostly it comes down to this:
- You have to have hacker skills. If you want to make sense of your data, you have to be able to wrangle it. The List was an Excel spreadsheet, and our case data were part of a SQL database. Your data will not start out pretty and uniform. You have to know how to work with them, how to get them out of difficult places, and how to do this at scale. Heck, you have to make them digestible for that machine learning model you built.
- You have to have substantive expertise. You have to know what questions to ask. Someone familiar with drug cases asked if people were being left off The List because their experience told them something was missing. If you do not know what questions to ask your data will never lead to insight.
- You have to know your stats. You have to know what the numbers mean. You have to know your error bars. It would be dramatic to shout, "We're missing 9,600 names!" Because as I discussed above, this is the top end of a range, but my guess is that reality lies closer to the lower end. That being said, I do not know exactly where because I was part of a small team, and we did not have the resources to look through hundreds of police reports. So the large error bars remain, but that is good because error bars keep us honest.
I find Conway's diagram compelling for two main reasons:
- It makes clear the interdisciplinary nature of data science.
- It works to show what data science is not.
The case of the rogue chemist is not the best example for exploring the exact boundaries of data science as it required very little heavy lifting. It was mostly an exercise in data cleaning and counting. However, the dirty secret of data science is that most of your time is spent wrangling data.You can see, however, that once we become more ambitious, these distinctions become important. Say we are interested in seeing how new court practices affect client outcomes, or we want to know if a certain law is disparately impacting minorities. Of course, we need to know our practice (substantive experience), but if we want to use data in real-time to make predictions or spot patterns, we will also need heavy integration with workflow and a good deal of iteration. We will need to hack. When we start to do more than count, we will need a better understanding of statistics to avoid making unwarranted claims through either incompetence or malice. Beware the danger zone! As Conway points out, "It is from this part of the diagram that the phrase ‘lies, damned lies, and statistics' emanates." Mathematician Cathy O'Neil warns against the use of algorithms as secret rules. She makes clear that models (in the form of algorithms) are not neutral. When powerful institutions use of math to make decisions, we need to be sure they show their work. Uses of predictive policing and "risk based" sentencing raise questions of fairness in our criminal justice system. Attorneys need the tools and expertise to check the work of opposing counsel. We need the ability to fight data with data.
Maybe data science is just a fancy name for scientific reasoning and applied statistics put to use in a nonacademic context, but if it takes Harvard Business Review declaring data scientist The Sexiest Job of the 21st Century to get people interested in collecting quality data and testing hypotheses, I'm willing to play along. Because at the end of the day, the stories of our data are the stories of our clients, and as advocates, it is our job to give them voice.
Last Updated: 2018-05-09